
转载自: mysql5.7生产环境使用mysqldump建议详解
目录
备份命令:mysqldump
MySQL数据库自带的一个很好用的备份命令。是逻辑备份,导出 的是SQL语句。也就是把数据从MySQL库中以逻辑的SQL语句的形式直接输出或生成备份的文件的过程。
参数解析
-A --all-databases:导出全部数据库
-Y --all-tablespaces:导出全部表空间
-y --no-tablespaces:不导出任何表空间信息
--add-drop-database每个数据库创建之前添加drop数据库语句。
--add-drop-table每个数据表创建之前添加drop数据表语句。(默认为打开状态,使用--skip-add-drop-table取消选项)
--add-locks在每个表导出之前增加LOCK TABLES并且之后UNLOCK TABLE。(默认为打开状态,使用--skip-add-locks取消选项)
--comments附加注释信息。默认为打开,可以用--skip-comments取消
--compact导出更少的输出信息(用于调试)。去掉注释和头尾等结构。可以使用选项:--skip-add-drop-table --skip-add-locks --skip-comments --skip-disable-keys
-c --complete-insert:使用完整的insert语句(包含列名称)。这么做能提高插入效率,但是可能会受到max_allowed_packet参数的影响而导致插入失败。
-C --compress:在客户端和服务器之间启用压缩传递所有信息
-B--databases:导出几个数据库。参数后面所有名字参量都被看作数据库名。
--debug输出debug信息,用于调试。默认值为:d:t:o,/tmp/
--debug-info输出调试信息并退出
--default-character-set设置默认字符集,默认值为utf8
--delayed-insert采用延时插入方式(INSERT DELAYED)导出数据
-E--events:导出事件。
--master-data:在备份文件中写入备份时的binlog文件,在恢复进,增量数据从这个文件之后的日志开始恢复。值为1时,binlog文件名和位置没有注释,为2时,则在备份文件中将binlog的文件名和位置进行注释
--flush-logs开始导出之前刷新日志。请注意:假如一次导出多个数据库(使用选项--databases或者--all-databases),将会逐个数据库刷新日志。除使用--lock-all-tables或者--master-data外。在这种情况下,日志将会被刷新一次,相应的所以表同时被锁定。因此,如果打算同时导出和刷新日志应该使用--lock-all-tables 或者--master-data 和--flush-logs。
--flush-privileges在导出mysql数据库之后,发出一条FLUSH PRIVILEGES 语句。为了正确恢复,该选项应该用于导出mysql数据库和依赖mysql数据库数据的任何时候。
--force在导出过程中忽略出现的SQL错误。
-h --host:需要导出的主机信息
--ignore-table不导出指定表。指定忽略多个表时,需要重复多次,每次一个表。每个表必须同时指定数据库和表名。例如:--ignore-table=database.table1 --ignore-table=database.table2 ……
-x --lock-all-tables:提交请求锁定所有数据库中的所有表,以保证数据的一致性。这是一个全局读锁,并且自动关闭--single-transaction 和--lock-tables 选项。
-l --lock-tables:开始导出前,锁定所有表。用READ LOCAL锁定表以允许MyISAM表并行插入。对于支持事务的表例如InnoDB和BDB,--single-transaction是一个更好的选择,因为它根本不需要锁定表。请注意当导出多个数据库时,--lock-tables分别为每个数据库锁定表。因此,该选项不能保证导出文件中的表在数据库之间的逻辑一致性。不同数据库表的导出状态可以完全不同。
--single-transaction:适合innodb事务数据库的备份。保证备份的一致性,原理是设定本次会话的隔离级别为Repeatable read,来保证本次会话(也就是dump)时,不会看到其它会话已经提交了的数据。
-F:刷新binlog,如果binlog打开了,-F参数会在备份时自动刷新binlog进行切换。
-n --no-create-db:只导出数据,而不添加CREATE DATABASE 语句。
-t --no-create-info:只导出数据,而不添加CREATE TABLE 语句。
-d --no-data:不导出任何数据,只导出数据库表结构。
-p --password:连接数据库密码
-P --port:连接数据库端口号
-u --user:指定连接的用户名。
--routines, -R 导出存储过程以及自定义函数。
--triggers 导出触发器
举例使用
1.导出整个实例所有数据库结构
如果是选全部数据,则系统的mysql库还是带着数据,个人创建的是只有结构
mysqldump -ugoodhope -pgoodhope --all-databases -d > all.sql
可以指定我们自己的库,那么备份出来的只有结构
mysqldump -ugoodhope -pgoodhope -d dbname > all.sql
2. 导出数据库下某个表数据
mysqldump -ugoodhope -pgoodhope dbname tablename > all.sql
导出test库下a表的数据加结构
mysqldump -ugoodhope -pgoodhope test107 a > all.sql
3.导出数据库中某个表结构(不包含数据)
mysqldump -ugoodhope -pgoodhope -d dbname tablename > all.sql
数据库tst107下a表的结构导出
mysqldump -ugoodhope -pgoodhope -d test107 a > all.sql
4.无参数备份单个库(生产不建议使用)
备份: mysqldump -ugoodhope -pgoodhope test107 > all.sql
创建库 :create database test107
还原库 :mysql -ugoodhope -pgoodhope dbname<all.sql
备份的文件中没有创建库和指定库
恢复时候我们需要先创建一个空库,然后在还原的时候还要指定该库才能正常还原,比较繁琐我们 不建议使用
5. 使用参数备份单个库(生产建议使用)
1.备份
mysqldump -ugoodhope -pgoodhope -B test107 > all.sql
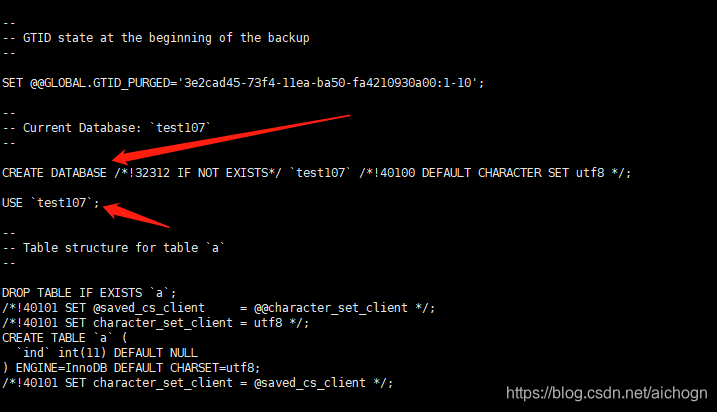
说明:加了-B参数后,备份文件中多的Create database和use mytest的命令
加-B参数的好处:
加上-B参数后,导出的数据文件中已存在创建库和使用库的语句,不需要手动在原库是创建库的操作,在恢复过程中不需要手动建库,可以直接还原恢复。
2.恢复操作
删除库(如果库已经存在)
mysql -ugoodhope -pgoodhope -e 'drop database test107;'
恢复
mysql -ugoodhope -pgoodhope <all.sql
6.压缩备份
mysqldump -ugoodhope -pgoodhope -B test107 | gzip > all.gz
产生压缩文件,
我们可以先解压看看备份数据
gzip -d all.gz
还原可以直接使用gz文件,也可以解压后使用解压的文件都是可以的
恢复
mysql -ugoodhope -pgoodhope <all.gz
7.备份多个库
通过-B值得顶多个库即可
mysqldump -ugoodhope -pgoodhope -B test107 testoracle | gzip > all.gz
8.分库备份
我们可以在上面单个库备份基础上执行多次,也可以使用一个指令来循环备份各个库
for dbname in ` mysql -ugoodhope -pgoodhope -e "show databases;" | grep -Evi "database|infor|perfor"`
do
mysqldump -ugoodhope -pgoodhope --events -B $dbname | gzip >${dbname}_bak.sql.gz
done
说明:${dbname}_bak,由于要求备份文件名以$dbname_bak.sql.gz格式命令,但系统无法辨别变量是$dbname还是$dbname_bak,所以此时就需要用大括号“{}”将变量括起来,就是${dbname}_bak.sql.gz了。
企业生产场景不同引擎备份命令参数
1、mysqldump的关键参数
-B:指定多个库,在备份文件中增加建库语句和use语句
--compact:去掉备份文件中的注释,适合调试,生产场景不用
-A:备份所有库
-F:刷新binlog日志
--master-data:在备份文件中增加binlog日志文件名及对应的位置点
-x --lock-all-tables:锁表
-l:只读锁表
-d:只备份表结构
-t:只备份数据
--single-transaction:适合innodb事务数据库的备份
InnoDB表在备份时,通常启用选项--single-transaction来保证备份的一致性,原理是设定本次会话的隔离级别为Repeatable read,来保证本次会话(也就是dump)时,不会看到其它会话已经提交了的数据。
2、不同引擎备份命令参数用法
1)Myisam引擎:
mysqldump -uroot -p123456 -A -B --master-data=1 -x| gzip > /data/all_$(date +%F).sql.gz
(2)InnoDB引擎:
mysqldump -uroot -p123456 -A -B --master-data=1 --single-transaction > /data/bak.sql
(3)生产环境DBA给出的命令
a、for MyISAM
mysqldump --user=root --all-databases --flush-privileges --lock-all-tables \
--master-data=1 --flush-logs --triggers --routines --events \
--hex-blob > $BACKUP_DIR/full_dump_$BACKUP_TIMESTAMP.sql
b、for InnoDB
mysqldump --ugoodhoe -pgoodhope --all-databases --flush-privileges --single-transaction \
--master-data=1 --flush-logs --triggers --routines --events \
--hex-blob > $BACKUP_DIR/full_dump_$BACKUP_TIMESTAMP.sql
MYSQL系列书籍
高可用mysql: https://url41.ctfile.com/f/49289241-959127723-de4738?p=2651 (访问密码: 2651)
MySQL王者晋级之路.pdf: https://url41.ctfile.com/f/49289241-959127432-204284?p=2651 (访问密码: 2651)
MySQL技术内幕InnoDB存储引擎第2版.pdf: https://url41.ctfile.com/f/49289241-959126379-4590a8?p=2651 (访问密码: 2651)
MySQL技术内幕 第4版.pdf: https://url41.ctfile.com/f/49289241-959125506-a5bcec?p=2651 (访问密码: 2651)
MySQL管理之道,性能调优,高可用与监控(第二版).pdf: https://url41.ctfile.com/f/49289241-959124249-d59f54?p=2651 (访问密码: 2651)
HIVE电子书
Practical Hive.pdf: https://url41.ctfile.com/f/49289241-959129883-d35ee9?p=2651 (访问密码: 2651)
Hive-Succinctly.pdf: https://url41.ctfile.com/f/49289241-959129709-30f30b?p=2651 (访问密码: 2651)
Apache Hive Essentials.pdf: https://url41.ctfile.com/f/49289241-959129691-b1a4aa?p=2651 (访问密码: 2651)
Apache Hive Cookbook.pdf: https://url41.ctfile.com/f/49289241-959129619-3a8ea6?p=2651 (访问密码: 2651)
hadoop电子书
Practical Hadoop Migration.pdf: https://url41.ctfile.com/f/49289241-959131470-dd3e24?p=2651 (访问密码: 2651)
Hadoop实战-陆嘉恒(高清完整版).pdf: https://url41.ctfile.com/f/49289241-959131365-433ec9?p=2651 (访问密码: 2651)
Hadoop & Spark大数据开发实战.pdf: https://url41.ctfile.com/f/49289241-959131032-ba40ea?p=2651 (访问密码: 2651)
Expert Hadoop Administration.pdf: https://url41.ctfile.com/f/49289241-959130468-ba70cd?p=2651 (访问密码: 2651)
Big Data Forensics - Learning Hadoop Investigations.pdf: https://url41.ctfile.com/f/49289241-959130435-9ab981?p=2651 (访问密码: 2651)
python电子书
python学习手册.pdf: https://url41.ctfile.com/f/49289241-959129403-5b45b1?p=2651 (访问密码: 2651)
Python基础教程-第3版.pdf: https://url41.ctfile.com/f/49289241-959128707-de6ef2?p=2651 (访问密码: 2651)
Python编程:从入门到实践.pdf: https://url41.ctfile.com/f/49289241-959128548-ce965d?p=2651 (访问密码: 2651)
Python Projects for Beginners.pdf: https://url41.ctfile.com/f/49289241-959128461-b53321?p=2651 (访问密码: 2651)
kafka电子书
Learning Apache Kafka, 2nd Edition.pdf: https://url41.ctfile.com/f/49289241-959134953-a14305?p=2651 (访问密码: 2651)
Kafka权威指南.pdf: https://url41.ctfile.com/f/49289241-959134932-295734?p=2651 (访问密码: 2651)
Kafka in Action.pdf: https://url41.ctfile.com/f/49289241-959134116-12111a?p=2651 (访问密码: 2651)
Apache Kafka实战.pdf: https://url41.ctfile.com/f/49289241-959133999-76ef77?p=2651 (访问密码: 2651)
Apache Kafka Cookbook.pdf: https://url41.ctfile.com/f/49289241-959132547-055c36?p=2651 (访问密码: 2651)
spark电子书
Spark最佳实践.pdf: https://url41.ctfile.com/f/49289241-959415393-5829fe?p=2651 (访问密码: 2651)
数据算法--Hadoop-Spark大数据处理技巧.pdf: https://url41.ctfile.com/f/49289241-959415927-5bdddc?p=2651 (访问密码: 2651)
Spark大数据分析实战.pdf: https://url41.ctfile.com/f/49289241-959416377-924161?p=2651 (访问密码: 2651)
Spark 2.0 for Beginners.pdf: https://url41.ctfile.com/f/49289241-959416710-7ea156?p=2651 (访问密码: 2651)
Pro Spark Streaming.pdf: https://url41.ctfile.com/f/49289241-959416866-6116d7?p=2651 (访问密码: 2651)
Spark in Action.pdf: https://url41.ctfile.com/f/49289241-959416986-e759e9?p=2651 (访问密码: 2651)
Learn PySpark.pdf: https://url41.ctfile.com/f/49289241-959417049-ac04a0?p=2651 (访问密码: 2651)
Fast Data Processing with Spark.pdf: https://url41.ctfile.com/f/49289241-959417157-8ec3b0?p=2651 (访问密码: 2651)
Fast Data Processing with Spark, 2nd Edition.pdf: https://url41.ctfile.com/f/49289241-959417211-856d08?p=2651 (访问密码: 2651)
OReilly.Learning.Spark.2015.1.pdf: https://url41.ctfile.com/f/49289241-959417292-90c1bc?p=2651 (访问密码: 2651)
High Performance Spark.pdf: https://url41.ctfile.com/f/49289241-959417439-7e7893?p=2651 (访问密码: 2651)
Machine Learning with PySpark.pdf: https://url41.ctfile.com/f/49289241-959417580-5941b3?p=2651 (访问密码: 2651)
Spark for Python Developers.pdf: https://url41.ctfile.com/f/49289241-959417721-d59fbe?p=2651 (访问密码: 2651)
Spark Cookbook.pdf: https://url41.ctfile.com/f/49289241-959417811-19c75d?p=2651 (访问密码: 2651)
Big Data Analytics with Spark.pdf: https://url41.ctfile.com/f/49289241-959417907-41dbce?p=2651 (访问密码: 2651)
PySpark SQL Recipes.pdf: https://url41.ctfile.com/f/49289241-959417970-c23242?p=2651 (访问密码: 2651)
Advanced Analytics with Spark Patterns for Learning from Data at Scale .pdf: https://url41.ctfile.com/f/49289241-959417997-a5e3f5?p=2651 (访问密码: 2651)
OReilly.Advanced.Analytics.with.Spark.Patterns.for.Learning.from.Data.at.Scale.pdf: https://url41.ctfile.com/f/49289241-959418024-2ff34c?p=2651 (访问密码: 2651)
Big Data Analytics Beyond Hadoop_ Real-Time Applications with Storm, Spark, and More Hadoop Alternatives.pdf: https://url41.ctfile.com/f/49289241-959418042-581fb9?p=2651 (访问密码: 2651)