
转载自: 分布式链路跟踪
文章目录
方案一:自己写代码完成链路跟踪

在zuul中添加过滤器:
package com.cloud.mszuul.filter;
import com.cloud.mszuul.Constants;
import com.netflix.zuul.ZuulFilter;
import com.netflix.zuul.context.RequestContext;
import com.netflix.zuul.exception.ZuulException;
import lombok.extern.slf4j.Slf4j;
import org.slf4j.MDC;
import org.springframework.stereotype.Component;
import javax.servlet.http.HttpServletRequest;
import java.util.Objects;
import java.util.UUID;
@Slf4j
@Component
public class RequestStatFilter extends ZuulFilter {
@Override
public String filterType() {
return "pre";
}
@Override
public int filterOrder() {
return 1;
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public Object run() throws ZuulException {
log.info("执行requestStatFilter");
String traceId = UUID.randomUUID().toString();
MDC.put("traceId",traceId);
RequestContext requestContext = RequestContext.getCurrentContext();
requestContext.addZuulRequestHeader("app\_trace\_id",traceId);
return null;
}
}
在serviceA中添加拦截器:
package com.cloud.servicea.interceptor;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang.StringUtils;
import org.slf4j.MDC;
import org.springframework.stereotype.Component;
import org.springframework.web.servlet.HandlerInterceptor;
import org.springframework.web.servlet.ModelAndView;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.util.UUID;
@Slf4j
@Component
public class LogInterceptor implements HandlerInterceptor {
private static final String TRACE_ID = "traceId";
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView arg3) throws Exception {
log.info("postHandle");
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String traceId = request.getHeader("app\_trace\_id");
if (StringUtils.isEmpty(traceId)) {
MDC.put(TRACE_ID, UUID.randomUUID().toString());
} else {
MDC.put(TRACE_ID, traceId);
}
log.info("preHandle");
return true;
}
}
给feign添加拦截器:
package com.cloud.servicea.feign;
import feign.RequestInterceptor;
import feign.RequestTemplate;
import org.slf4j.MDC;
import org.springframework.context.annotation.Configuration;
@Configuration
public class FeignInterceptorConfig implements RequestInterceptor{
private static final String TRACE_ID = "traceId";
@Override
public void apply(RequestTemplate requestTemplate) {
requestTemplate.header(TRACE_ID,MDC.get(TRACE_ID));
}
}
使用这个拦截器:
package com.cloud.servicea.config;
import com.cloud.servicea.interceptor.LogInterceptor;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
import javax.annotation.Resource;
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Resource
private LogInterceptor logInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(logInterceptor)
.addPathPatterns("/\*\*");
}
}
添加logback的配置
<?xml version="1.0" encoding="UTF-8"?>
<!--scan: 当此属性设置为true时,配置文件如果发生改变,将会被重新加载,默认值为true。
scanPeriod: 设置监测配置文件是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。当scan为true时,此属性生效。默认的时间间隔为1分钟。
debug: 当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。-->
<configuration scan="true" scanPeriod="10 seconds">
<contextName>JPANAME</contextName>
<property name="log.path" value="C:\\Users\\CNALWEI\\source\\springcloud\\logs\\servicea"/>
<property name="server.name" value="auth-api-ext-impl"/>
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符-->
<property name="log.pattern" value="%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} ::[trace=%X{X-B3-TraceId}, span=%X{X-B3-SpanId}] %msg%n"/>
<property name="log.file" value="${log.path}/${server.name}.%d{yyyyMMdd}.%i.log.gz"/>
<!-- 控制台输出 -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>${log.pattern}</pattern>
</encoder>
</appender>
<appender name="fileAppender" class="ch.qos.logback.core.rolling.RollingFileAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>${log.pattern}</pattern>
</encoder>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!--日志文件输出的文件名-->
<FileNamePattern>${log.file}</FileNamePattern>
<!--日志文件保留天数-->
<MaxHistory>30</MaxHistory>
<maxFileSize>50MB</maxFileSize>
</rollingPolicy>
<ImmediateFlush>true</ImmediateFlush>
</appender>
<appender name="asyncFileAppender" class="ch.qos.logback.classic.AsyncAppender">
<queueSize>5000</queueSize>
<discardingThreshold>0</discardingThreshold>
<includeCallerData>false</includeCallerData>
<appender-ref ref="fileAppender"/>
</appender>
<!--这里可以不写-->
<logger name="com.feng" level="INFO"></logger>
<!-- 日志输出级别 -->
<root level="INFO">
<appender-ref ref="asyncFileAppender"/>
<appender-ref ref="console"/>
</root>
</configuration>
方案二:Spring Cloud Sleuth + ZipKin
借用Google的Dapper,Twitter的Zipkin。
Sleuth原理
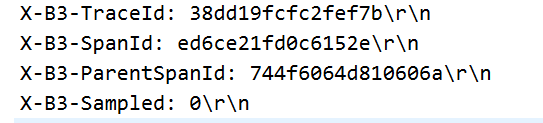
可以看到,在请求头信息中多了 4 个属性:
- x-b3-spanid:一个工作单元(rpc 调用)的唯一标识。
- span是sleuth中最基本的工作单元,一个微服务收到请求后会创建一个span同时产生一个span id,span id是一个64位的随机数,sleuth将其转化为16进制的字符串,打印在日志里面。其对应的实现类是RealSpan。
- x-b3-parentspanid:当前工作单元的上一个工作单元,Root Span(请求链路的第一个工作单元)的值为空。
- x-b3-traceid:一条请求链条(trace) 的唯一标识。
- 在一个调用链条中,trace id是始终不变的,每经过一个微服务span id生成一个新的,所以通过trace id可以找出调用链上所有经过的微服务。trace id默认是64位,可以通过spring.sleuth.traceId128=true设置trace id为128位。调用链的第一个服务,其span id和trace id是同一个值。
- x-b3-sampled:是否被抽样为输出的标志,1 为需要被输出,0 为不需要被输出。
note: 以上通过x-b3-spanid、x-b3-traceid、x-b3-parentspanid这三个值即可复现整个链路。如下图所示

Sleuth实现
在工程中添加Sleuth包,则能够自动实现方案一的过程,并不需要手工设置。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
<version>2.1.7.RELEASE</version>
</dependency>
这里可阅读Sleuth的源码

在服务间的传递过程中,HTTP的Header会出现如下几个参数:
为了能够打印,则需要在日志配置文件中添加%X{X-B3-TraceId}
<!-- 控制台输出 -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout">
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level logName:%logger{36} - [trace=%X{X-B3-TraceId}, span=%X{X-B3-SpanId}] - Msg:%msg%n%n</pattern>
</layout>
</encoder>
</appender>
Sleuth源码分析(todo)
方案三:Skywalking
无代码侵入。国产开源框架,2015年开源。
Skywalking 是使用 Java Agent 服务器探针来收集和发送数据到归集器。
首先从官方网站上下载对应的包。本地地址:C:\Users\CNALWEI\Downloads\apache-skywalking-apm-es7-7.0.0.tar\apache-skywalking-apm-bin-es7
在IDEA中部署探针:
-javaagent:C:\Users\CNALWEI\Downloads\apache-skywalking-apm-es7-7.0.0.tar\apache-skywalking-apm-bin-es7\agent\skywalking-agent.jar -Dskywalking.agent.service_name=zuul
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-73xo6yLH-1648037347005)(img/image-20220111172755879.png)]](https://img-blog.csdnimg.cn/a64bc976a70d42dca35721e71e8ead03.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2WAOmk2Q-1648037347006)(img/image-20220111172736354.png)]](https://img-blog.csdnimg.cn/3dc730476efd4d75be2a9d5d921cafa9.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6a2P5LqR6IiS,size_20,color_FFFFFF,t_70,g_se,x_16)
在pom中添加三方包:
<!--skywalking traceId 记录到logback日志-->
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-logback-1.x</artifactId>
<version>8.3.0</version>
</dependency>
在添加配置文件logback-spring.xml
<!-- 控制台输出 -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<!-- <encoder>-->
<!-- <pattern>${log.pattern}</pattern>-->
<!-- </encoder>-->
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout">
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level logName:%logger{36} - [%tid] - Msg:%msg%n%n</pattern>
</layout>
</encoder>
</appender>
当你使用-javaagent参数激活sky-walking的探针, 如果当前上下文中存在traceid,logback将在输出traceId。如果探针没有被激活,将输出TID: N/A.而且SkyWalking是基于字节码增强的,traceId的传递依赖于SkyWalking的服务端,如果服务端异常等客户端连接不上服务端的情况,就会出现TID: [Ignored Trace]的情况。
由于之前选择了SkyWalking作为服务链路监控工具,所以自然而然想到SkyWalking中的traceId是否能复用到日志中。日志的traceId是否有,依赖SkyWalking的服务端与客户端的连接。某些场景下,可能会丢失traceId。所以考虑到第二种方案就是通过Spring Cloud Sleuth生成和传递traceId,但是对源码有一定的侵入性。所以在方案选择的时候,可以根据实际情况选择。