
大家好,我是你们的技术博主枫夜求索阁!
在人工智能技术飞速发展的今天,DeepSeek以革命性创新重新定义了AI模型的边界。从开源策略到混合专家架构,从多模态处理到垂直领域深耕,它的技术突破如同为AI世界注入一剂强效催化剂。当传统大模型受限于高昂成本和单一模态时,DeepSeek通过MLA注意力机制、MoE架构等创新,实现了低成本训练与高效推理的完美平衡。本文将用生活化案例拆解技术原理,带您看懂这个"AI万花筒"如何用开源精神、工程智慧与算法创新,在医疗、金融、教育等领域掀起智能革命。
deepseek的创新之处
按照不同例子进行解释:
生活化例子
- 开源策略:就像开源软件让普通人也能用上高级编程工具,DeepSeek的开源模型让全球开发者都能用上顶尖AI技术,就像每个人都能用上免费的高级计算器。
- 低成本训练:就像用普通食材做出高级美食,DeepSeek用较少的资源训练出高性能模型,就像用普通食材做出高级美食。
- 推理架构创新:就像用更快的交通方式到达目的地,DeepSeek的推理架构优化让模型响应更快,就像用高铁代替绿皮火车。
- 多模态处理:就像一个全能翻译官,既能说英语又会写代码,DeepSeek能处理文本、图像、音频等多种信息。
- 垂直领域应用:就像一个万能工具箱,DeepSeek在医疗、金融、教育等多个领域都能派上用场。
概念讲解
- 开源策略:DeepSeek选择将模型开源,这意味着全球的开发者都可以查看、修改和使用其技术,促进了技术的快速发展和普及。
- 低成本训练:通过创新的架构设计和算法优化,DeepSeek大幅降低了训练大模型所需的资源,使得更多机构和个人能够参与到AI研究中。
- 推理架构创新:DeepSeek采用了新的推理架构,如混合专家模型(MoE)和多头潜在注意力机制(MLA),这些创新提升了模型的处理能力和效率。
- 多模态处理:DeepSeek不仅能理解和生成文本,还能处理图像、音频等多模态数据,这使得它在更复杂的任务中表现出色。
- 垂直领域应用:DeepSeek在医疗、金融、教育等多个领域开发了专门的模型,以满足不同行业的需求,推动了AI技术在各个领域的应用。
简单记法
- 开源策略:开源=开放+共享,让技术飞入百姓家。
- 低成本训练:用更少的钱,做更多的事。
- 推理架构创新:架构创新=更快的马,更远的路。
- 多模态处理:一机多用,样样精通。
- 垂直领域应用:专精一门,行行出状元。
图示

deepseek推理结构的技术创新之处与技术原理
创新之处
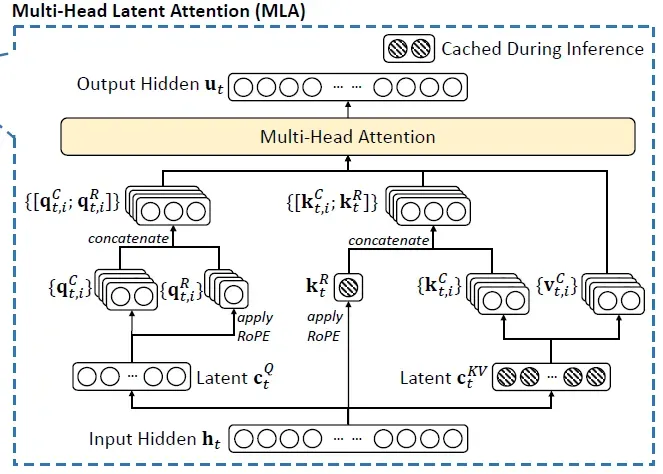
- 多头潜在注意力(MLA)
- 通过低秩键值(KV)联合压缩技术,将每个查询的KV缓存量减少93.3%,显著降低显存消耗,同时提升推理效率。
- 该技术源自DeepSeek-V2,后续可能演进为量化MLA(QMLA)或压缩MLA(CMLA)。
- 混合专家模型(MoE)架构
- 采用DeepSeek-MoE策略,在推理时仅激活部分专家模块,避免全参数激活带来的计算浪费,训练成本降低50%以上。
- 例如,DeepSeek-V3使用61个MoE block,总参数达671B,但推理时仅激活少量专家链路。
- 混合精度训练框架
- 在非关键模块使用FP8低精度存储数据,减少内存占用和计算复杂度,同时通过高精度累积解决量化误差问题。
- 强化学习与思维链技术结合
- 通过大规模强化学习(RL)优化推理策略,将数学、代码等任务的奖励信号泛化到通用推理场景,提升跨任务能力。
- 生成详细思维链(Chain of Thought),将复杂问题拆解为多步中间推理,增强可解释性。
技术原理
- MLA的实现原理
- 低秩近似:将高维KV矩阵分解为低秩矩阵的乘积,减少存储和计算量。例如,将128×128的KV矩阵压缩为16×128和128×16的矩阵相乘。
- 缓存优化:通过压缩后的KV缓存,模型在相同显存容量下存储更多缓存数据,提升长序列处理能力。
- 强化学习驱动推理
- 策略优化:采用群体相对策略优化(GRPO),通过组内评分估计基线,简化计算过程,降低强化学习对标注数据的依赖。
- 多阶段训练:先训练推理导向的中间模型(如R1-Zero),再通过该模型生成高质量训练数据,最终微调出通用推理模型。
- 思维链技术的运作机制
- 问题分解:将复杂任务(如数学证明)拆解为多个子问题,每一步生成中间推理步骤并评估其对最终结果的贡献。
- 动态规划:结合知识图谱和外部知识库,动态调整推理路径,确保逻辑连贯性和答案准确性。
此架构通过高效推理与深度思考的结合,实现了高性能与低成本的双重突破。
结尾
DeepSeek的技术版图正以开源为笔,创新为墨,在人工智能的画卷上勾勒出独特风景。从压缩93.3%显存消耗的MLA机制,到激活效率提升50%的MoE架构;从FP8混合精度训练到强化学习驱动的思维链,这些创新不仅是技术参数的突破,更是AI普惠化的重要里程碑。当更多开发者能在开源生态中构建专属AI工具,当企业能用更低成本享受智能升级,DeepSeek正在证明:技术创新不应是少数人的特权,而应是推动全行业进化的公共引擎。这场由架构创新引发的AI效率革命,才刚刚拉开序幕。